Processor Affinity
Each JURECA compute node consists of two sockets, each with one CPU. Each CPU has 64 physical and 128 logical cores, so that one JURECA compute node consists of 128 physical and 256 logical cores. Each CPU is split into four separate NUMA domains for a total of eight NUMA domains per node.
Binding a process or thread to a specific core - known as pinning - can improve the performance of your code by limiting the likelihood of remote memory accesses. Once your code runs and produces correct results on a system, the next step is performance improvement. The placement of processes and/or threads can play a significant role in performance for a process that uses multiple cores or accelerator hardware.
In general, the Linux scheduler will periodically (re-)distribute all running processes across all available threads to ensure similar usage of the threads. This leads to processes being moved from one thread, core, or socket to another within the compute node. Note that the allocated memory of a process does not necessarily move at the same time (or at all), which can make access to memory much slower. To avoid a potential performance loss due to process migration, processes are usually pinned (or bound) to a logical core through the resource management system. In the case of JURECA, this is Slurm. A pinned process (consisting of one or more threads) is bound to a specific set of cores and will only run on the cores in this set. The set can be a single core or multiple cores that implicitly includes 1st and 2nd level caches associated with those cores and is defined with an affinity mask. Since the majority of applications benefit from strict pinning that prevents migration – unless explicitly prevented – all tasks in a job step are pinned to a set of cores by default. Further information about the default behaviour can be found below.
Note
SchedMD has adapted the behavior of the pinning with Slurm version 22.05 (Currently installed version: 23.02). Whilst our customised default setting improves the performance of average applications over no process binding at all, specialised settings for your application can yield even better performance. Pay attention to maximizing data locality while minimizing latency and resource contention, and have a clear understanding of the characteristics of your own code and the machine that the code is running on.
JURECA-DC NUMA domain default:
The JURECA-DC CPU and GPU Slurm partition has configured 16 CPU cores in each of the 4 NUMA domains per socket (NPS-4), resulting in 8 NUMA domains for the 2 socket systems (0-7). Not all sockets have a direct connection (affinity) to each GPU or HCA. To keep the NUMA to core assignment equally configured on the entire JURECA-DC system we have the GPU partition configuration also configured at the CPU partition:
NUMA Domain ID |
GPU ID |
Core IDs |
|---|---|---|
3 |
0 |
48-63, 176-191 |
1 |
1 |
16-31, 144-159 |
7 |
2 |
112-127, 240-255 |
5 |
3 |
80-95, 208-223 |
2 |
32-47, 160-175 |
|
0 |
0-15, 128-143 |
|
6 |
96-111, 224-239 |
|
4 |
64-79, 192-207 |
More details can be found here.
Slurm options
Slurm allows users to modify the process affinity by means of the --cpu-bind, --distribution and --hint options to srun.
While the available options to srun are standard across all Slurm installations, the implementation of process affinity is done in plugins and thus may differ between installations.
On JURECA a custom pinning implementation is provided by Partec (psslurm).
In contrast to other options, the processor affinity options need to be directly passed to srun and must not be given to sbatch or salloc.
In particular, the option cannot be specified in the header of a batch script.
Warning
srun will no longer read in SLURM_CPUS_PER_TASK and will not inherit option --cpus-per-task from sbatch!
This means you will explicitly have to specify --cpus-per-task to your srun calls, or set the new SRUN_CPUS_PER_TASK env var.
If you want to keep using --cpus-per-task with sbatch then you will have to add: export SRUN_CPUS_PER_TASK=${SLURM_CPUS_PER_TASK}.
Warning
Setting the option --cpus-per-task implies the option --exact, which means that each step with --cpus-per-task will now only receive the minimum number of cores requested for that job step.
The pinning will change (which has an implication on the performance) and can mean threads of different tasks can share the same core (using SMT).
Attention: As a result, explicitly setting --cpus-per-task=1 may result in a different affinity mask than using the implicit default, which is also 1.
Note
As we expect that most of our users will neither want to use nor benefit from SMT, we have disabled SMT by default by setting --threads-per-core=1.
To use SMT, the --threads-per-core=2 option must be set for sbatch or salloc.
Just setting it as a srun option is not enough.
Attention: In our tests we have seen that enabling SMT can lead to suboptimal, non-intuitive affinity masks.
Warning
We recommend not to use --cpu-bind=sockets if you use more tasks than sockets, otherwise tasks will share the same hardware threads.
If --cpus-per-task is to be used together with --cpu-bind=sockets, then you usually want to override the implicit --exact by specifying --overcommit so that a task is allocated the full socket.
Warning
Setting --hint can lead to unexpected pinning as it is mutually exclusive with with the following options:
--ntasks-per-core, --threads-per-core, -B and --cpu-bind (other then --cpu-bind=verbose).
We recommend not using the --hint option.
Note
For hybrid and pure OpenMP applications, it is important to specify the correct number of --cpus-per-task to ensure a proper affinity mask and set the OMP_NUM_THREADS environment variable accordingly.
However, the individual threads of each MPI rank can still be moved between the logical threads matching the affinity mask of this rank. OMP_PROC_BIND=true can be used to prevent thread movement. For more advanced, OpenMP-internal affinity specifications, consult the documentation for OMP_PLACES or vendor-specific alternatives (KMP_AFFINITY/GOMP_CPU_AFFINITY).
Terminology
- thread
One CPU thread.
- task
Part of a job consisting of a number of requested CPU threads (specified by
-c, --cpus-per-task).- core
One physical CPU core can run multiple CPU threads. The CPU threads sitting on the same physical core share caches.
- socket
Consists of a number of CPU threads, corresponding to the NUMA domains detailed above.
--cpu-bind
--cpu-bind=[{quiet,verbose},none|rank|map_cpu:<list>|mask_cpu:<list>|rank_ldom|map_ldom:<list>|mask_ldom:<list>|sockets|cores|threads|ldoms|boards]
Implicit types
|
Do not bind tasks to CPUs |
|
Each task is pinned to as many threads as it requests. Which threads each process
gets is controlled by the
--distribution option. (Default) |
|
Each task is pinned to as many threads as it requests, just filling cores
consecutively. Spread the threads and tasks to as many cores as possible.
This type is not influenced by the second and third part of the
--distributionoption. (old default until 12th May 2020)
|
|
Each task is pinned to as many threads as it requests, just filling the nodes
rank by rank cycling sockets and cores. This type is not influenced by the second
and third level of the –distribution option. The threads of a task are always
packed to as few cores as possible. This is the same as
--cpu-bind=threads --distribution=*:cyclic:block |
|
In a first step the requested CPU threads of a task are assigned in exactly the
same way as with
--cpu-bind=threads. But the final affinity mask for the taskis the whole socket where any thread is located that it is assigned to. This means
if a task is assigned to any thread that is part of a socket, it will be bound to
the whole socket. (The ‘whole’ here means to each thread of the socket that is
allocated to the job)
|
|
In a first step the requested CPU threads of a task are assigned in exactly the
same way as with
--cpu-bind=threads. But the final affinity mask for the taskis the whole core where any thread is located that it is assigned to. This means
if a task is assigned to any thread that is part of a core, it will be bound to
the whole core. (The ‘whole’ here means to each thread of the core that is
allocated to the job)
|
|
This is the same as |
|
Currently not supported on systems with more than one board per node.
JURECA has only one board: same behavivor as
none |
Explicit types
|
Explicit passing of maps or masks to pin the tasks to threads in a round-robin fashion. |
|
|
|
Explicit passing of maps or masks to pin the tasks to sockets in a round-robin fashion. |
|
Note
Explicitly specified masks or bindings are only honored when the job step has allocated every available CPU on the node.
If you want to use a map_ or mask_ bind, then you should have the steps request a whole allocation
(do not use --exact or --cpus-per-task or --exclusive).
You also may want to use --overlap so that other steps can also allocate all of the cpus and you have control over
the task to cpu binding via one of the map or mask options for --cpu-bind.
--distribution
The string passed to --distribution/-m can have up to four parts separated by colon and comma:
The first part controls the distribution of the task over the nodes.
The second part controls the distribution of tasks over sockets inside one node.
The third part controls the distribution of tasks over cores inside one node.
The fourth part is an additional information concerning the distribution of tasks over nodes.
--distribution/-m=<node_level>[:<socket_level>[:<core_level>[,Pack|NoPack]]]
First part (node_level)
|
The default is |
|
Distribute tasks to a node such that consecutive tasks share a node |
|
Distribute tasks to a node such that consecutive tasks are distributed over
consecutive nodes (in a round-robin fashion)
|
|
|
|
Second part (socket_level)
|
The default is |
|
Each socket is first filled with tasks before the next socket will be used. |
|
Each task will be assigned to the next socket(s) in a round-robin fashion. |
|
Each thread inside a task will be assigned to the next socket in a round-robin
fashion, spreading the task itself as much as possible over all sockets.
fcyclic implies cyclic. |
Third part (core_level)
|
The default is inherited from the second part |
|
Each core is first filled with tasks before the next core will be used. |
|
Each task will be assigned to the next core(s) in a round-robin fashion.
The threads of a task will fill the cores.
|
|
Each thread inside a task will be assigned to the next core in a round-robin
fashion, spreading the task itself as much as possible over all cores.
|
Fourth part
Optional control for task distribution over nodes.
|
Default is NoPack. See: https://slurm.schedmd.com/srun.html |
|
--hint
We do not recommend using this option, as our tests have shown that it can lead to unexpected pinning.
Possible values are nomultithread, compute_bound, and memory_bound (They imply other options).
--hint=nomultithread
Affinity visualization tool
We have tried to understand and implement the Slurm affinity rules. The result is our PinningWebtool, which allows you to test and visualise different Slurm affinity setups yourself. A description of the displayed scheme can be found in the section below.
Affinity examples
Visualization of the processor affinity in the following examples is done by the tool jscgetaffinity (a wrapper for psslurmgetbind) which is also available on the login nodes of JURECA.
The scheme shown represents a node of JURECA which has two sockets divided by the space in the middle, and each socket is in turn divided into 4 NUMA domains.
Each column corresponds to one core; the first row shows the first (physical) thread of the corresponding core and the second row the SMT (logical thread) of the core.
The number (X) followed by a : in the line above the described scheme represents the MPI task number for which the affinity mask is shown in the scheme.
The number 1 in the scheme itself indicates that the task with its threads is scheduled on the corresponding hardware thread of the node.
Example: One MPI task with two threads:
For the purpose of presentation, 0..0 indicates that not all hardware threads of a NUMA domain on a JURECA node are shown
(on a JURECA there are 16 physical and 16 SMT threads per NUMA domain).
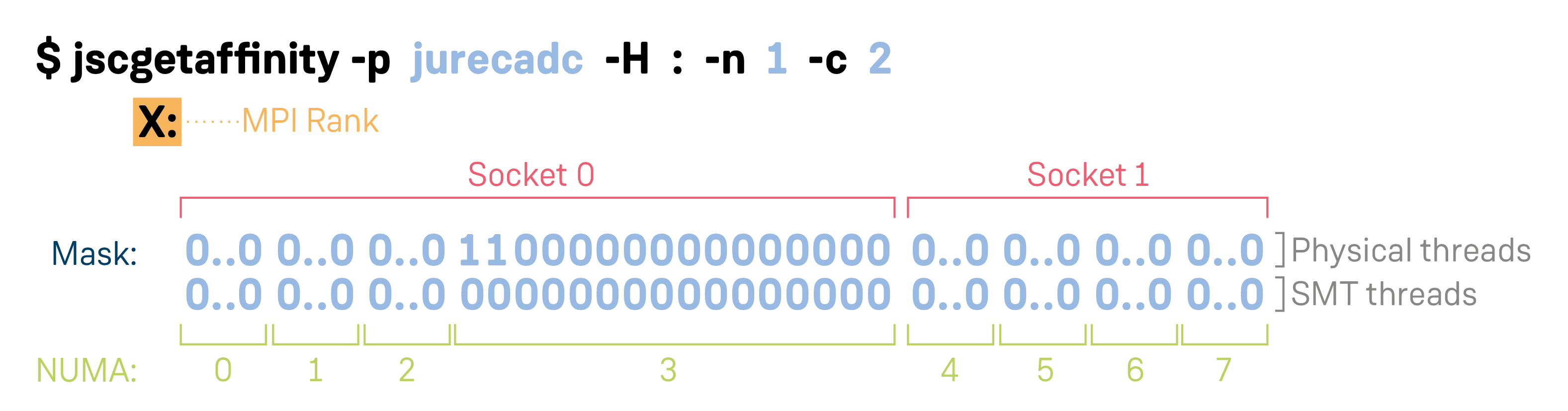
Default processor affinity
The default processor affinity has changed at 6th August 2024 to the following setting:
--cpu-bind=threads --distribution=block:cyclic:cyclic --threads-per-core=1
The behavior of this combination is shown in the following examples for JURECA.
For the purpose of presentation, 0..0 indicates that not all cores of a NUMA domain on a JURECA node are shown.
Example 1: Pure MPI application filling only the first thread of a core on a node in alternating socket placement:
srun --nodes=1 --ntasks=128 --cpus-per-task=1
$ jscgetaffinity -p jurecadc -H : -n 128 -c 1
0:
0..0 0..0 0..0 1000000000000000 0..0 0..0 0..0 0..0
0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0
1:
0..0 1000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
0..0 0000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
2:
0..0 0..0 0..0 0..0 0..0 0..0 0..0 1000000000000000
0..0 0..0 0..0 0..0 0..0 0..0 0..0 0000000000000000
3:
0..0 0..0 0..0 0..0 0..0 1000000000000000 0..0 0..0
0..0 0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0
4:
0..0 0..0 1000000000000000 0..0 0..0 0..0 0..0 0..0
0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0 0..0
5:
1000000000000000 0..0 0..0 0..0 0..0 0..0 0..0 0..0
0000000000000000 0..0 0..0 0..0 0..0 0..0 0..0 0..0
6:
0..0 0..0 0..0 0..0 0..0 0..0 1000000000000000 0..0
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000000 0..0
7:
0..0 0..0 0..0 0..0 1000000000000000 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
...
126:
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000001 0..0
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000000 0..0
127:
0..0 0..0 0..0 0..0 0000000000000001 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
Example 2: Hybrid application (MPI + OpenMP) with 16 tasks per node in round-robin socket placement and 8 threads per task on a node:
Hint: As stated in the note above, it is your responsibility to take care of the thread binding within the mask provided by Slurm to prevent the threads from moving. As a good starting point, you could add the following extra line to your job script:
export OMP_PLACES=threads OMP_PROC_BIND=close OMP_NUM_THREADS=8
srun --nodes=1 --ntasks=16 --cpus-per-task=8
$ jscgetaffinity -p jurecadc -H : -n 16 -c 8
0:
0..0 0..0 0..0 1111111100000000 0..0 0..0 0..0 0..0
0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0
1:
0..0 1111111100000000 0..0 0..0 0..0 0..0 0..0 0..0
0..0 0000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
...
7:
0..0 0..0 0..0 0..0 1111111100000000 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
8:
0..0 0..0 0..0 0000000011111111 0..0 0..0 0..0 0..0
0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0
...
14:
0..0 0..0 0..0 0..0 0..0 0..0 0000000011111111 0..0
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000000 0..0
15:
0..0 0..0 0..0 0..0 0000000011111111 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
Example 3: Pure OpenMP application with 128 threads on a node:
Hint: As stated in the note above, it is your responsibility to take care of the thread binding within the mask provided by Slurm to prevent the threads from moving. As a good starting point, you could add the following extra line to your job script:
export OMP_PLACES=threads OMP_PROC_BIND=close OMP_NUM_THREADS=128
srun --nodes=1 --ntasks=1 --cpus-per-task=128
$ jscgetaffinity -p jurecadc -H : -n 1 -c 128
0:
1111111111111111 1111111111111111 1111111111111111 1111111111111111 1111111111111111 1111111111111111 1111111111111111 1111111111111111
0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000000
Further examples
Example 1: Pure MPI application filling all all threads on a node (including SMT):
Hint: Don’t forget to add
--threads-per-core=2also forsbatchorsalloc: In your job script:#SBATCH --threads-per-core=2
#SBATCH --threads-per-core=2
srun --nodes=1 --ntasks=256 --cpus-per-task=1
$ jscgetaffinity -p jurecadc -H : -n 256 -c 1
0:
0..0 0..0 0..0 1000000000000000 0..0 0..0 0..0 0..0
0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0
1:
0..0 1000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
0..0 0000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
...
126:
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000001 0..0
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000000 0..0
127:
0..0 0..0 0..0 0..0 0000000000000001 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
128:
0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0
0..0 0..0 0..0 1000000000000000 0..0 0..0 0..0 0..0
129:
0..0 0000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
0..0 1000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
...
254:
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000000 0..0
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000001 0..0
255:
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000001 0..0 0..0 0..0
Example 2: Hybrid application (MPI + OpenMP) with 16 tasks per node in a consecutive order according to the reordering of the NUMA domains and with 8 threads per task on a single node:
Hint: As stated in the note above, it is your responsibility to take care of the thread binding within the mask provided by Slurm to prevent the threads from moving. As a good starting point, you could add the following extra line to your job script:
export OMP_PLACES=threads OMP_PROC_BIND=close OMP_NUM_THREADS=8
srun --nodes=1 --ntasks=16 --cpus-per-task=8 --cpu-bind=rank
$ jscgetaffinity -p jurecadc -H : -n 16 -c 8 --cpu-bind=rank
0:
0..0 0..0 0..0 1111111100000000 0..0 0..0 0..0 0..0
0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0
1:
0..0 0..0 0..0 0000000011111111 0..0 0..0 0..0 0..0
0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0 0..0
2:
0..0 1111111100000000 0..0 0..0 0..0 0..0 0..0 0..0
0..0 0000000000000000 0..0 0..0 0..0 0..0 0..0 0..0
...
13:
0..0 0..0 0..0 0..0 0..0 0..0 0000000011111111 0..0
0..0 0..0 0..0 0..0 0..0 0..0 0000000000000000 0..0
14:
0..0 0..0 0..0 0..0 1111111100000000 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
15:
0..0 0..0 0..0 0..0 0000000011111111 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000000000000000 0..0 0..0 0..0
Example 3: Hybrid application (MPI + OpenMP) with 16 tasks per node and
12 threads per tasks. If you want to us more than tasks-per-node * cpus-per-tasks > 128
per node on JURECA you have to add --threads-per-core=2:
Hint: Don’t forget to add
--threads-per-core=2also forsbatchorsalloc: In your job script:#SBATCH --threads-per-core=2Hint: As stated in the note above, it is your responsibility to take care of the thread binding within the mask provided by Slurm to prevent the threads from moving. As a good starting point, you could add the following extra line to your job script:
export OMP_PLACES=threads OMP_PROC_BIND=close OMP_NUM_THREADS=12
#SBATCH --threads-per-core=2
srun --nodes=1 --ntasks=16 --cpus-per-task=12
$ jscgetaffinity -p jurecadc -H : -n 16 -c 12
0:
0..0 0..0 0..0 1111110000000000 0..0 0..0 0..0 0..0
0..0 0..0 0..0 1111110000000000 0..0 0..0 0..0 0..0
1:
0..0 1111110000000000 0..0 0..0 0..0 0..0 0..0 0..0
0..0 1111110000000000 0..0 0..0 0..0 0..0 0..0 0..0
...
7:
0..0 0..0 0..0 0..0 1111110000000000 0..0 0..0 0..0
0..0 0..0 0..0 0..0 1111110000000000 0..0 0..0 0..0
8:
0..0 0..0 0..0 0000001111110000 0..0 0..0 0..0 0..0
0..0 0..0 0..0 0000001111110000 0..0 0..0 0..0 0..0
...
14:
0..0 0..0 0..0 0..0 0..0 0..0 0000001111110000 0..0
0..0 0..0 0..0 0..0 0..0 0..0 0000001111110000 0..0
15:
0..0 0..0 0..0 0..0 0000001111110000 0..0 0..0 0..0
0..0 0..0 0..0 0..0 0000001111110000 0..0 0..0 0..0
Example 4: Pure OpenMP application with 128 threads and SMT enabled:
Hint: Don’t forget to add
--threads-per-core=2also forsbatchorsalloc: In your job script:#SBATCH --threads-per-core=2Hint: As stated in the note above, it is your responsibility to take care of the thread binding within the mask provided by Slurm to prevent the threads from moving. As a good starting point, you could add the following extra line to your job script:
export OMP_PLACES=threads OMP_PROC_BIND=close OMP_NUM_THREADS=128
#SBATCH --threads-per-core=2
srun --nodes=1 --ntasks=1 --cpus-per-task=128
$ jscgetaffinity -p jurecadc -H : -n 1 -c 128 --threads-per-core=2
0:
0..0 1111111111111111 0..0 1111111111111111 0..0 1111111111111111 0..0 1111111111111111
0..0 1111111111111111 0..0 1111111111111111 0..0 1111111111111111 0..0 1111111111111111
Examples for manual pinning
For advanced use cases it can be desirable to manually specify the binding masks or core sets for each task.
This is possible using the options --cpu-bind=map_cpu and --cpu-bind=mask_cpu.
For example,
srun -n 2 --cpu-bind=map_cpu:1,5
spawns two tasks pinned to core 1 and 5, respectively. The command
srun -n 2 --cpu-bind=mask_cpu:0x3,0xC
spawns two tasks pinned to cores 0 and 1 (0x3 = 3 = 2^0 + 2^1) and cores 2 and 3 (0xC = 12 = 2^2 + 2^3), respectively.