Access
This article describes how to access JURECA using SSH.
Prerequisites
In order to gain access to JURECA you have to be given access to a resource pool on the system. This can happen in one of two ways:
Apply for a computing time allocation
You can apply for your own computing time allocation through our Coordination Office for the Allocation of Computing Time. This means you have to write a proposal that details your scientific goals and the technical aspects of the work you intend to do. Our web site has more details on how to apply for computing time.
Ask to join an existing project
If you join or collaborate with a team which already has been granted resources on JURECA then you can ask to join their computing time project through our web portal JuDoor. Our web site describes how to join a computing time project through JuDoor.
SSH Login
This section describes the login procedure using the Secure Shell Protocal (SSH). Alternative methods are available and documented elsewhere, see Alternative Login Methods.
SSH is an open protocol, that allows users to log in to a remote server system from a local client system. There are free programs for the most common operating systems that implement the SSH protocol. Details are discussed for both OpenSSH (GNU/Linux, macOS, etc.) and PuTTY (Microsoft Windows).
Restrictions
Due to security concerns, several restrictions have been placed on what SSH login credentials are allowed and which set of features can be used:
You cannot log in using username/password credentials. Instead, password free login based on public key cryptography is required.
Your private key has to be stored in a file that is encrypted using a secure passphrase.
When uploading a public key to our systems, you also have to declare a set of hosts or subnets which you want to log in from.
Modifications to the list of authorized keys can only be performed via JuDoor.
Too many accesses within a short amount of time will be interpreted as an intrusion and will lead to automatically disabling the originating system at the FZJ firewall.
As of May 2020, storage of any private keys on the storage resources at JSC are prohibited, with limited exceptions. Please contact the support team at sc@fz-juelich.de concerning the use of codes requiring system-internal SSH access.
Agent-forwarding is turned off server-side on all systems at JSC.
These restrictions imply that outgoing SSH connections are not allowed.
See the dedicated section on using Git under these restrictions
OpenSSH
OpenSSH is a popular and freely available SSH client (and server) for UNIX-like operating systems such as GNU/Linux and macOS.
OpenSSH Installation
OpenSSH comes pre-installed on macOS.
It is also contained in the package repository of many GNU/Linux distributions, e.g. openssh-client on Debian, Ubuntu, etc. or openssh-clients on Fedora, Centos, etc.
As a last resort, the OpenSSH source code can be downloaded from the OpenSSH web site.
OpenSSH Key Generation
At JSC, we do not allow logging into our systems solely with a password; rather, we require key-based authentication.
It is important to generate secure key pairs. The current best key type is called Ed25519. Generate a key of this type with the following line
$ ssh-keygen -a 100 -t ed25519 -f ~/.ssh/id_ed25519
The options specify the type of the key (-t), the number of key derivation function rounds (-a), and the location to place the key (-f), which is selected to be the default.
Optionally, one can give a comment to the key with -C to help distinguish multiple keys.
Note
If the file ~/.ssh/id_ed25519 already exists, ssh-keygen will ask before overwriting it.
You probably do not want to overwrite the file as you might already be using it as credentials for another system.
Instead, use a different file name, e.g. ~/.ssh/id_ed25519_jsc and remember to use the same file name on all subsequent command lines in this document.
Afterwards, ssh-keygen will ask for a passphrase.
It is imperative to provide a strong passphrase at this point, i.e. one that cannot easily be guessed or found by brute force.
It needs to be entered in the future to unlock your private key.
You might want to use a password manager to save your key and ease the use of complicated passphrases.
Note
It is not allowed to store private keys which you use to log in to systems at JSC without protecting them by a passphrase!
Keep the private part (i.e., ~/.ssh/id_ed25519) of the key-pair safe, confidential, and on your local host only.
The generated public key (in the example above ~/.ssh/id_ed25519.pub) needs to be uploaded to the HPC systems via JuDoor.
Key Upload, Key Restriction
Public keys are uploaded to Jülich HPC systems via the user portal JuDoor (https://judoor.fz-juelich.de/) for each system separately. Make sure you are uploading the key to the desired system by clicking the “Manage SSH-keys” button beside the respective system name. Once uploaded, the key will be available on the system within 15 minutes.
Uploaded public keys need to be additionally restricted to allow access only from certain connection sources. This is an additional security measure to prevent access from unknown computers.
Restriction is solved via the from clause in SSH.
The from clause is added before the public key during upload in the format
from="192.0.2.42" ssh-ed25519 AAAAC3N….
In this case, the SSH daemon on JURECA would only allow connections to the system using the key in question if the connection originates from 192.0.2.42. Please note that 192.0.2.42 is solely provided as an example and will never be a useful from clause.
The content of the from clause, the 192.0.2.42 in the example above, is a comma-separated list of IP addresses or hostnames, which can also include partial patterns. If one of the patterns match, access to the system is granted. The following options for patterns are possible:
A literal IP address, like
192.0.2.42(IPv4) or2001:db8::2a(IPv6)A literal hostname, like
host.example.comAn IP address or hostname with wildcard operators, like
*.example.comAn IP address range in CIDR notation, like
192.51.100.0/24(IPv4) or2001:db8:4815:1623::/64(IPv6)
Note
JURECA can be reached via IPv6.
If you are connecting from a machine with working IPv6 connectivity, your SSH client will prefer IPv6 and you will need to specify a from clause based on your IPv6 address.
You can check your IPv6 connectivity by trying to ping JURECA, ping -6 jureca.fz-juelich.de or ping6 jureca.fz-juelich.de, or by visiting an IPv6 test site in your web browser, e.g. https://test-ipv6.com.
If you prefer to connect via IPv4, there are several ways to force your SSH client to use IPv4 only which will be described below under Logging in to JURECA, OpenSSH Configuration, and PuTTY Configuration.
An example of a combination of the patterns:
from="2001:db8::2a,192.51.100.0/24,*.fz-juelich.de" ssh-ed25519 AAAAC3N…
It would allow a specific IP address (2001:db8::2a), would allow an entire subnet (192.51.100.1 to 192.51.100.254), and additionally allow connections from hostnames ending on .fz-juelich.de.
Warning
Patterns with the wildcard operator * in the last position (such as hostname.* or 192.51.100.*) are not allowed.
By allowing an arbitrary suffix, patterns of this form make it easy for an attacker to create a reverse DNS entry that matches (e.g. hostname.attacker.com or 192.51.100.attacker.com).
Please restrict your from clause as much as possible. It strongly increases the security of your account and with that the security of the whole system. Here are some hints and thoughts about choosing a good set of from patterns:
If you know that your connections will come from a single address or a small range of addresses, specify that address or range. For example, academic institutions often have access to a fixed range of IP addresses and might even assign a single fixed address to your machine. The department in charge of networking should be able to tell you more. Even if you are not on-site and might work from somewhere else, you probably have a VPN which can connect you into the network of the institution. You can then use that to connect to our system. (Forschungszentrum Jülich uses public IPv4 addresses from
134.94.0.0/16and IPv6 addresses from2001:638:404::/48.)Internet service providers often assign IP addresses dynamically to customers, so the address you connect from can change over time (in some cases daily). In these cases, it is most practical to make the
fromclause allow any address that your ISP might possibly assign to you. This can be done using patterns based on either IP addresses (IPv4 or IPv6) or DNS host names.Based on IP address ranges: Some ISPs only have a small number of ranges of IP addresses allocated to them. For IPv6, in many cases it is just one range. For IPv4, the number of address ranges allocated to a provider can be quite large in some cases and this method becomes impractical. If you can find out the ranges allocated to your ISP, you can list them separated by comma in the
fromclause. Here are two methods for finding that information:Look up the allocations in a table: Lists of allocations can be found online such as this list of allocations for German internet providers. (Lists for other countries are available from the overview page, look in the “Number of addresses” column.)
Use a WHOIS lookup: The registries in charge of address range allocations run databases that can be queried using the WHOIS protocol. This can be done using the command line
whoistool or web based lookup tools. Given an IP address (either IPv4 or IPv6) these tools will return information about who this address is allocated to as part of what address range. The following listing shows an excerpt of running thewhoisutility on an IPv6 address assigned to FZJ:$ whois 2001:db8::2a [...] # whois.ripe.net inet6num: 2001:db8::/48 netname: DOC-NET descr: Documentation ISP descr: Not a real ISP, just for documentation purposes descr: Documentationstadt country: DE [...]
The format of the output can vary from one registry to another, but it will have a block regarding the allocation to your ISP that (in the case of IPv6) will show the address range in the CIDR notation expected by SSH. Here
2001:db8::/48would be a good candidate for thefromclause.Note
WHOIS only tells you about the one allocation range of the IP address you asked about, while a provider can have multiple ones. This means that a
fromclause based on this range only might not be exhaustive.Warning
Only address ranges with a netmask >= 8 are allowed for both IPv4 and IPv6.
Based on host names: Patterns can be based on host names if your ISP has configured reverse DNS entries for their address ranges. In our experience this is not commonly done for IPv6 addresses, but is still quite common for IPv4. For IPv4 especially, host name based patterns can be used as a good work around for cases where the IPv4 address ranges of an ISP are too fragmented to comfortably use in a
fromclause.Get your IP by asking your favourite search engine “what is my IP”;
Look up the hostname associated to your IP address; call
nslookup <your IP>in a shell or search online for “display my hostname”;Try to understand the hostname generation scheme of your internet provider and place a wildcard (
*), defining a pattern as coarsely as needed and as tightly as possible. For example, if your IP resolves to2909a2-ip.nrw.provider.net, placing*.nrw.provider.netcould be a good bet. Don’t be too generous with the wildcards here, it has the potential to allow unwanted access!
Warning
When using
*the whole ISP name has to be given as a minimum, e.g.*.fz-juelich.de. Wider ranges like*.deare not allowed.
JSC is currently reviewing the access policy and may enforce additional measures in the near future. Please try to limit the range of source systems as much as possible so that less modifications are required later.
More on the from clause and further clauses which can improve the security of your account can be found in the sshd(8) (man sshd on a system, or the online version of sshd(8)) and ssh_config(5) (man ssh_config on a system, or the online version of ssh_config(5)) man pages.
Logging in to JURECA
To login to JURECA, please use
$ ssh -i ~/.ssh/id_ed25519 <yourid>@jureca.fz-juelich.de
$ ssh -4 -i ~/.ssh/id_ed25519 <yourid>@jureca.fz-juelich.de # Restrict SSH client to IPv4
$ ssh -i ~/.ssh/id_ed25519 <yourid>@jureca-ipv4.fz-juelich.de # IPv4 only host name
<yourid> is your user id at JSC (e.g. mustermann1).
You will be prompted for the passphrase of the ssh key which is the one you entered when you generated the key (see above).
With your first connection to the HPC system, you will also be asked to check the host key fingerprint of the system you log in to.
This fingerprint is displayed in JuDoor next to the form you use to upload your public key.
Please compare the host key fingerprint from JuDoor to the one printed during your first login!
Only if both are identical, proceed to connect to the system.
If they don’t match, please inform JSC via sc@fz-juelich.de
Note
Recent versions of OpenSSH (starting with version 8.0 from April 2019) instead of forcing you to do the comparison manually and answer yes/no will also allow you to copy and paste the key fingerprint as found in JuDoor.
The ssh client will then perform the comparison for you and abort if there is a mismatch.
In general, it makes sense to have one key-pair per source system from which you connect to the HPC systems, e.g. your laptop and your desktop computers.
In addition, you might want to generate individual keys for specific use-cases.
Use a non-standard key during your SSH connection with ssh -i path/to/nonstandard/key or by adding it to your key agent or providing an entry in your SSH configuration (see Key Agent and OpenSSH Configuration).
Key Agent
If you chose a strong passphrase for your brand-new Ed25519 key, you might be annoyed by having to enter it for every connection. You don’t need to be. An SSH agent can be used to remember the passphrase for you.
An SSH agent (or similar service, possibly provided by a password manager or your desktop) is probably started on your system automatically, check if ssh-add -l returns an error.
If an agent is running, you can add any SSH key you have generated via
$ ssh-add ~/.ssh/id_ed25519
assuming you have used the path and key stated above.
Without arguments, ssh-add will look for keys of all supported types in their default locations.
SSH keys can also be added automatically as soon as you start using them via an option in SSH configuration (see OpenSSH Configuration), then no extra command is necessary.
Check keys stored in your agent with ssh-add -l or their public keys with ssh-add -L.
Both commands will include the comment you have provided during key generation.
You can limit the life-time of keys stored in the agent by supplying -t <seconds> as an option.
This provides more control and ensures keys are not stored indefinitely (i.e. until the agent is restarted).
Agents might also interplay with the keychain of your operating system.
OpenSSH Configuration
The user-side SSH configuration can be used to create shortcuts to targets / hosts and configure connections.
These shortcuts and options also influence the behaviour of any program that uses SSH underneath, such as git, scp, and rsync.
An overview of all the available options can be seen via man ssh_config.
That’s probably overwhelming, so here are a few options and configurations highlighted.
The entries go into ~/.ssh/config.
The following entry creates a shortcut that allows you to refer to jureca.fz-juelich.de and its individual log in nodes jureca01.fz-juelich.de, jureca02.fz-juelich.de (see MFA with TOTP), etc. via the short names jureca and jureca01, jureca02, etc.
Host jureca jureca??
Hostname %h.fz-juelich.de
To configure settings for connections to JURECA, follow the shortcut entry by a configuration entry like this:
Match Host jureca.fz-juelich.de,jureca??.fz-juelich.de
User mustermann1
IdentityFile ~/.ssh/id_ed25519_jsc
Afterwards, connecting to JURECA is as easy as typing ssh jureca (instead of the equivalent but bulky ssh -i ~/.ssh/id_ed25519_jsc mustermann1@jureca.fz-juelich.de).
Added benefit: Copying a file from JURECA with scp can also make use of the alias: scp jureca:~/file.txt ~/.
Wildcards are supported as well. An example which sets your username for all Jülich systems:
Match Host *.fz-juelich.de
User some1
Further interesting options are highlighted in the following example entry
Match Host showoptions
ForwardX11 Yes # Be aware of security implications!
# Always together with "ForwardX11Trusted No"! See note!
ForwardX11Trusted No # Be aware of security implications! Never use "Yes"! See note below!
ForwardAgent No # Agent forwarding is not allowed on our systems
AddKeysToAgent Confirm # Add key used for this host to SSH agent, and confirm on every use
LogLevel Verbose # For finding out what's going wrong
Port 2222 # If connecting to an SSH server on a non-default port (=22)
AddressFamily inet # Restrict SSH to IPv4
X Forwarding
Launching GUI applications on remote systems can involve forwarding the X window to your source system – this is usually called X forwarding or X11 forwarding.
Using X forwarding with ssh -X (or ForwardX11 Yes in the SSH configuration) is considered secure, but some applications do not work with this option.
SSH provides a less secure alternative, ssh -Y (or ForwardX11Trusted Yes), which does indeed often work with forwarded applications.
But this connection is not secure; the target system is trusted blindly!
An attacker with root privileges on the target system has the ability to listen to every keystroke in your local X window environment.
Don’t use X forwarding with -Y!
If you can not use -X with the application of your choice, rather fall back to launching a VNC server on the target machine and connect to it via SSH port forwarding.
To use X Forwarding together with ssh multiplexing, it must be present in your ssh config. This is covered in the section MFA Persistent Connection.
Troubleshooting
If you have trouble connecting to one of our systems, please run the SSH client with verbose output:
$ ssh -vvv <yourid>@jureca.fz-juelich.de
Send the resulting output to the support team at sc@fz-juelich.de with a description of your problem.
Further Reading
ssh(1) man page (
man sshon a system, or the online version of ssh(1))ssh_config(5) man page (
man ssh_configon a system, or the online version of ssh_config(5))ssh-add(1) man page (
man ssh-addon a system, or the online version of ssh-add(1))ssh-agent(1) man page (
man ssh-agenton a system, or the online version of ssh-agent(1))ssh-keygen(1) man page (
man ssh-keygenon a system, or the online version ssh-keygen(1))
PuTTY
PuTTY is a popular and freely available SSH client for Microsoft Windows. The following guide will give an overview about the stand alone usage of PuTTY, not the integration into larger client tools such as MobaXTerm.
PuTTY Installation
The latest version of PuTTY can be downloaded at https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html which is the official website of the PuTTY developer.
When downloading new versions of PuTTY, always verify the URL and the HTTPS connection (typically visualized by your browser).
Do not use PuTTY executables out of untrusted sources!
PuTTY can be fully installed on your system or just be downloaded as an individual binary file which can be placed anywhere within your folders and needs no installation permissions for execution.
When downloading the individual binaries make sure to download putty.exe, puttygen.exe, and pageant.exe.
PuTTY Key Generation
Key handling within PuTTY is done with the tool called puttygen.exe.
It allows you to create new keys, open existing keys or convert keys between different formats.
To create a new key, open the tool.
Select Ed25519 for the key type (you need a current version of puttygen.exe to select this key type).
Afterwards click on Generate to start generating the key. You have to move your mouse until the full key is generated, this creates some randomness within the key pattern.
Afterwards set a Key comment. Here it is recommended to add your username and the system name where you generated the key.
Finally you have to select a Key passphrase. The passphrase is used to protect your key file on your local system. The passphrase will never be transferred to an external system. It is imperative to provide a strong passphrase at this point, i.e. one that cannot easily be guessed or found by brute force. It needs to be entered in the future to unlock your private key.
Note
It is not allowed to store private keys which you use to log in to systems at JSC without protecting them by a passphrase!
Using Save private key creates an encrypted .ppk private key file.
Keep this file confidential, and on your local host only.
Never send it to us or any other person!
You can always use puttygen.exe and the Load button together with your passphrase to reopen a .ppk file.
The public part of your key is directly displayed in the PuTTY Key Generator window itself:
Public key for pasting into OpenSSH authorized_keys file
The generated public key text (in the example below ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIAVbTcHgGDpiLJ+Sn8DgeRzIRlzTESOMMGcr9jUwZjLO user@systemname) needs to be uploaded to the HPC systems via JuDoor.
Warning
During upload with JuDoor, certain additional restrictions need to be applied; please see the paragraph above relating to Key Upload and Restriction.
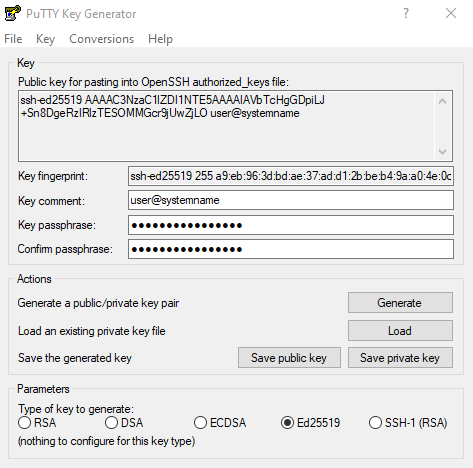
PuTTY Configuration
Start putty.exe to configure your SSH connection.
PuTTY allows to store all settings in a so called Session.
You can create a new Session by setting a Session name and hitting the Save button.
Keep in mind to always use the Save button after you changed the current selected Session.
You can use Load to load the configuration of an existing Session.
The first important configuration option is the Host Name of the system you want to access.
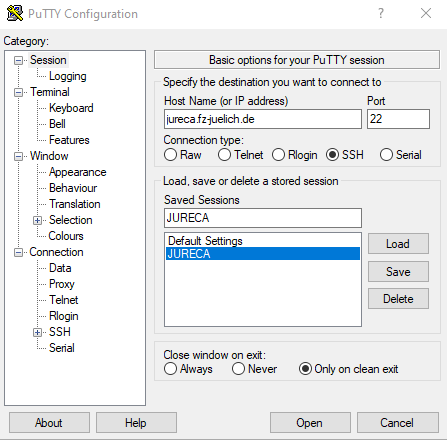
To select your generated SSH key, you have to browse to the page of the PuTTY configuration window.
Here you can select your private key .ppk file.
You should also allow agent forwarding.
By selecting this option authentication requests from other machines (e.g. if you want to access another system via SSH behind your first access) will then be forwarded back onto the first originating machine, e.g. your local host.
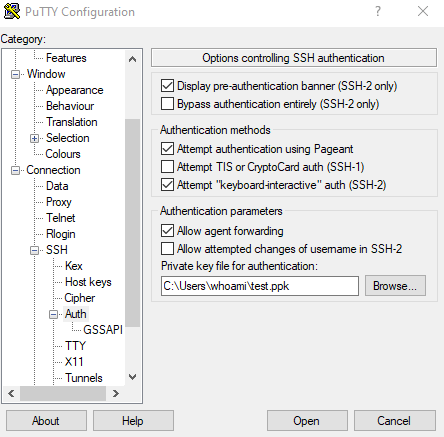
If you access a system for the first time, PuTTY will show an alert message. The message will point you to the fingerprint of the target system. You can compare the shown fingerprint to the system specific host fingerprints which are provided within the key upload page in JuDoor. Please compare the host key fingerprint from JuDoor to the one printed during your first login! Only if both are identical, proceed to connect to the system. If they don’t match, please inform JSC via sc@fz-juelich.de
Other useful configuration options are located in:
: The setting Internet protocol version can be used to restrict PuTTY to IPv4.
: Here you can store your personal username, which avoids entering this name during every login.
: Allows to enable X11 forwarding. In parallel you need a running XServer for Windows (e.g. XMing) on your local system.
MFA with TOTP
JuDoor allows users to enable multifactor authentication (MFA). When in use, logging into JSC Services will require a second factor with a timebased one-time password (TOTP). JuDoor also allows users to enable MFA for SSH login. If enabled, the ssh service on the login hosts of JURECA will prompt the user to enter the 6-digit token, after authentication via ssh-pubkey has succeeded.
$ ssh <yourid>@jureca.fz-juelich.de
(<yourid>@$jureca.fz-juelich.de) JSC TOTP Verification code:
If a valid token is entered the login process continues as usual.
If the entered token is not accepted the following message is printed:
TOTP token invalid. (Note: tokens can only be used once).
Reasons why a token is not accepted might be:
Reason |
Description |
Solution |
Token wrong |
Maybe just a typo? |
Please retry |
Token wrong |
The token-generator requires a
correct clock setting to generate
correct tokens.
|
Please verify the clock setting
and try again.
|
Token re-use |
The standard for TOTP requires that
tokens are used only once (time
based one-time passwords). Tokens
are valid within a time window of 30
seconds. Each time window results
in a distinct token.
|
Please wait and try again. |
Secrets differ |
TOTP relies on a shared secret key
between JSC and the user.
|
Verify you are using the correct
TOTP secret. Check at JuDoor.
|
Service/Network outage |
In order to protect the secret keys
at JSC, they are not copied to all
systems. Instead, services send a
verification request to the user
management service.
|
For user accounts which authenticate with either ssh keys from FIDO authenticators (e.g. yubikeys) or ssh-certificates (only EuroHPC users), the MFA (TOTP verification) is skipped.
Further information about TOTP:
TOTP is defined in RFC6238
MFA Persistent Connection
Sometimes it may be advantageous to have multiple simultaneous ssh connections to one of our endpoints.
To avoid TOTP authentication for each ssh connection to an endpoint, you can route multiple ssh connections through one main connection, using the ControlMaster SSH option
(also known as SSH multiplexing).
This is only possible on Linux and Mac systems as the OpenSSH implementation on Windows does not support this feature.
To use persistent connections for all domains (including any not administered by JSC), add the below code block to your ~/.ssh/config file:
Host *
ControlPath ~/.ssh/control-%h-%p-%r
ControlMaster auto
ControlPersist 8h
This will create a control file in the .ssh directory in your home directory for each unique host, port and username (%h, %p, %r respectively).
ControlPersist can be set as required and creates a timeout for the main connection.
Up until this timeout all subsequent ssh connections from the same client to the same server will not require authentication with ssh key or TOTP, even if you close the terminal with the original ssh session.
As a side effect, all ssh sessions will go through the same Login Node, as they all use the same persistent connection.
However, restarting the system the client is running on will require a new authentication.
This may be useful for remotely administered automated workflows.
If you create a session initially in this manner, then all following automated sessions can use this method to connect within the ControlPersist period.
Note
To use X Forwarding on any multiplexed ssh shell, it must also be included in ~/.ssh/config. All ssh shells connect to the same endpoint using the same ssh connection, and therefore X Forwarding must be turned
on for all connections to the hosts you wish to use it for.
To configure this, please follow the instructions in OpenSSH Configuration.
Note
Please note that the above code block will use a persistent ssh connection with any domain due to the use of Host *.
To use persistent connections only for JSC systems, you can relace Host * in the above code block with the lines:
CanonicalizeHostname yes
Match canonical host="*.fz-juelich.de"
These features may only function on newer SSH clients, or with particular approaches to setting up your ~/.ssh/config file, so the Host * approach should remain your default if this does not work.
Login Nodes
The JURECA system is accessible via ssh through the following login nodes:
Generic Names: |
|
Specific Names: |
jureca01, jureca02, jureca03, jureca04, jureca05,jureca06, jureca07, jureca08, jureca09, jureca10,jureca11, jureca12 |
Domain: |
|
The JURECA-HWAI system is accessible via ssh through the following login nodes:
Generic Names: |
|
Specific Names: |
|
Domain: |
|
Users outside the FZ campus have to use fully qualified names including the domain name. When using the generic name, a connection is established to one of the login nodes in the JURECA pool. Initiating two logins in sequence may lead to sessions on different nodes. In order to force the session to be started on the same nodes use the specific node names instead.
Warning
Login nodes are shared between all users of JURECA. Running unsuitable workloads on login nodes, i.e. spawning large number of processes or using a large fraction of the available memory, can affect other users. For this reason, the number of parallel processes is limited to 20, and memory consumption is limited to 25% of the total memory of the node. If usage from a single user exceeds this, their processes will be ended.
Note
Please note that individual login nodes may be in maintenance at any time. Users are advised not to rely on the availability of specific login nodes in their workflows.
Example
$ ssh <yourid>@jureca.fz-juelich.de
$ ssh <yourid>@jureca01.fz-juelich.de
Alternative Login Methods
Apart from login via SSH, JSC also offers login via UNICORE and Jupyter.