High Performance Storage Tier CSCRATCH
The high-performance storage tier (HPST) is a performance-optimized low-capacity tier that utilizes nonvolatile memory technologies (NVMe).
It is a cache layer on top of the $SCRATCH file system providing high bandwidth and low latency access. Its purpose is to speed up I/O
in compute jobs.
The HPST provides one global namespace and is accessible on JUSUF, JURECA-DC and JUWELS login and compute nodes.
Each compute cluster has its own part (slice) in the global cache and will use it for writing data. However clients can read data from the foreign slices as well.
Access is available to all projects with access to $SCRATCH. Please note that if large space is consumed, a quota limitation will be imposed on the project when required. For projects with a need for more space than the preset cutoff for imposing the limitation (currently set at 20TB), please contact the user support (sc@fz-juelich.de)
Note
Official support for the HPST will end on the 31st of March 2024.
Usage Concept
The HPST is not a separate storage space. It is a cache layer on top of the $SCRATCH file system.
As a result it behaves different than other file systems and while data can be copied to it using simple copy commands, it is important to understand where the data is stored and where it is accessed.
This section will explain three typical access types to the HPST. It is important to understand that any interaction with the HPST using special commands is done prior to or after the compute job. The application access to the HPST can be done using the regular POSIX and MPI-IO API calls.
The specific commands to interact with HPST corresponding to the described usage concepts can be found in Using CSCRATCH
Note that in the following description we use $CSCRATCH to refer to the HPST.
Read
In order to improve read performance using the HPST, the data has to be first prestaged to $CSCRATCH. Once the data has been transferred, the compute system can access the data from $CSCRATCH directly. When the data is no longer required on $CSCRATCH, space can be freed using purge.
The accelerated read process using $CSCRATCH is depicted in the figure below.
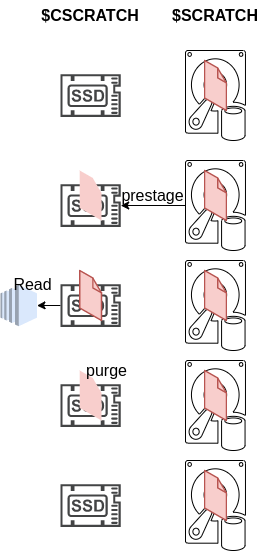
Copyright - FZ Jülich
Whenever data is not prestaged, it remains accessible to read through the $CSCRATCH. However, the data will be fetched from the underlying Backend-Filesystem (in this case $SCRATCH), which will result in slower read performance. That behavior is depicted in the figure below.
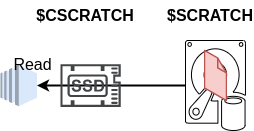
Write
$CSCRATCH can be written to directly. However, files written to $CSCRATCH will not be synchronized automatically back to $SCRATCH and at this stage there remains two versions of the file (the file is said to be Dirty). Once the sync operation is performed the file version in $CSCRATCH overwrites the file in $SCRATCH. When the data is no longer required on $CSCRATCH, space can be freed using purge.
The accelerated write process using $CSCRATCH is depicted in the figure below.
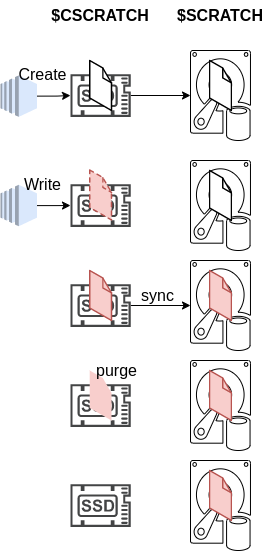
Copyright - FZ Jülich
Warning
$CSCRATCH is a cache layer. Be aware that if a file is cached and independently modified in the underlying file system $SCRATCH this can result in unexpected behavior. The data in the cache can get lost or the modifications in the underlying file system might get overwritten. Either way data will be lost. Note that in some cases (for example reaching a cache filling limit), data will be automatically staged out.
Read-Modify-Write
The above read and write operations can be combined in whatever configuration required. For example, in a read-modify-write, the data can be prestaged, edited and later synced. When data is no longer required on $CSCRATCH, space can be freed using purge.
The accelerated read-modify-write process using $CSCRATCH is depicted in the figure below.
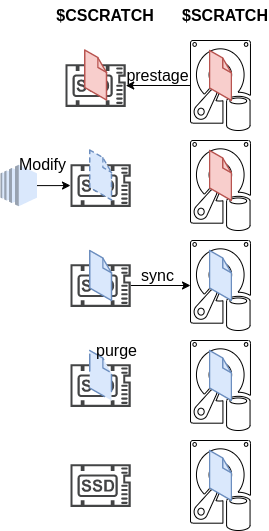
Copyright - FZ Jülich
Warning
CSCRATCH is a cache layer. Be aware that if a file is cached and independently modified in the underlying file system $SCRATCH this can result in unexpected results. The data in the cache can get lost or the modifications in the underlying file system might get overwritten. Either way data will be lost. Note that in some cases (for example reaching a cache filling limit), data will be automatically staged out.
General Information
Data and Metadata: It is important to know that metadata operations (e.g. creating a file) are synchronous operations and will depend on the response time of the underlying file system (in this
$SCRATCH). Data operations like writing to a file are operations on the cache and benefit from the performance.Inode Quota: On CSCRATCH quota usage is also defined. The inode quota (number of files) depends on the inode quota in
$SCRATCHbecause metadata operations are synchronous operations. Creating a new file can only succeed if there is at least one inode available in the underlying file system.Data Quota: For data blocks there is a project quota on CSCRATCH in place, which is 20 TB by default. It is a soft quota, meaning that creating more data will not be blocked, but an automatic staging out will be triggered by the system which may have a bad impact on the current IO performance. Use
jutilto display the quota values:
[user1@jsfl01 ~]$ jutil project dataquota -p chpsadm -U TB
project unixgroup storage filesystem fs-type project-dir data-usage data-soft-limit data-hard-limit inode-usage inode-soft-limit inode-hard-limit last-updated
-------- ---------- ------- ----------- -------- -------------------------- ---------- --------------- --------------- ----------- ---------------- ---------------- -------------------
chpsadm chpsadm just project project /p/project/chpsadm 0.015TB 14.901TB 16.391TB 21614 3000000 3300000 2022-02-08 00:22:50
chpsadm chpsadm just scratch scratch /p/scratch/chpsadm 0.015TB 90.000TB 95.000TB 66 4000000 4400000 2022-02-08 00:26:53
chpsadm chpsadm just cscratch cscratch /p/cscratch/fs/chpsadm 0.008TB 20.000TB 20.000TB 0 - - 2022-02-08 07:45:19
Note
Some projects do not have a set quota limit. If large space is consumed, a quota limitation will be imposed on the project when required. For projects with a need for more space than the preset cutoff for imposing the limitation (currently set at 20TB), please contact the user support (sc@fz-juelich.de)
Technical overview
The HPST is intended as a high bandwidth low latency I/O system. This is implemented using a NVMe storage cluster which is managed by the Infinite Memory Engine (IME) from DDN.
Each of the three attached client clusters (JUWELS, JURECA-DC and JUSUF) have their own slice. However, all three slices exist in the same namespace. Writing from the client side will always land in the assigned slice, while a pre-staged file could be divided across multiple slices. The ime-ctl command can be used as given in the following sections to check which slices the file resides on, where slice 0, 1 and 2 represents the JUWELS, JURECA-DC and JUSUF slice respectively.
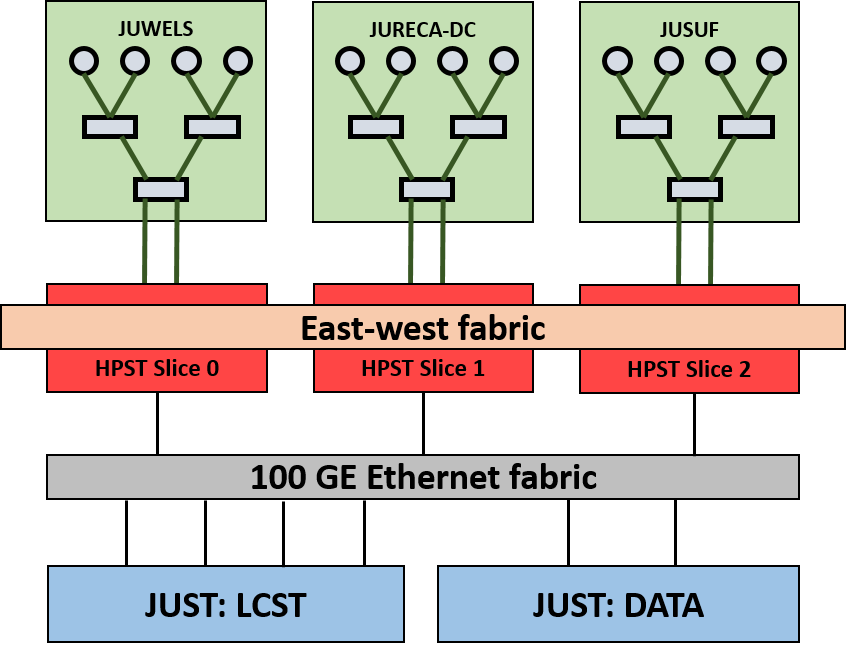
Copyright - FZ Jülich
As seen from the above figure, the HPST is integrated into the fabric of the three client clusters JUWELS, JURECA-DC and JUSUF. The HPST operates as a cache layer on top of the SCRATCH file system.
- The HPST is composed of 110 Server IME-140, each having
2 x HDR 100 (North connection)
1 x HDR 100 (East-West connection)
1 x 100 GE (South connection)
10 x NVMe drives (2TB) for HPST data
1 x internal NVMe IME commit log device
Slice |
Raw size |
|---|---|
JUWELS |
1036 TB |
JURECA-DC |
844 TB |
JUSUF |
230 TB |
Total |
2110 TB |
Using CSCRATCH
The shell variable $CSCRATCH is pointing to the location in CSCRATCH which is caching the files of $SCRATCH. (Remember to activate the project’s environment. The following examples use jutil env activate -p chpsadm)
As it is a cache the user has to take care of the state of each file. The user’s command line tool is ime-ctl (IME client file control):
Usage: ime-ctl {--prestage|--purge|--sync|--frag-stat} [OPTIONS] <PATH>
Commands:
--prestage Prestage file data from BFS to IME.
--purge Remove file data from IME
--sync Synchronize IME file data to BFS.
--frag-stat Get state of IME file data.
-v, --version Display version information.
Command Options:
--block Block on import or sync completion.
-R, --recursive Recursively run command on all directory entries.
Output Options:
-H, --human Convert byte values to human readable format.
--short Display short output format.
-V, --verbose Display verbose output.
Note
Any interaction with the HPST using special commands is done prior to or after the compute job. The application access to the HPST can be done using the regular POSIX and MPI-IO API calls.
Warning
To ensure the availability of $CSCRATCH during job submission, add fs:cscratch@just to the globres variable when allocating or submitting a job (See Job submission when using $CSCRATCH).
Acronym |
Meaning |
Description |
|---|---|---|
IME |
Infinite Memory Engine |
Software solution for the HPST |
BFS |
Backend File System |
underlying file system, here: |
Example:
$ ime-ctl --frag-stat $CSCRATCH/example/result.data
File: `/p/cscratch/fs/chpsadm/example/result.data'
Number of bytes:
Dirty: 0
Clean: 8136949760
Syncing: 251658240
Data on Slices: 2
Description |
|
|---|---|
Dirty |
Number of bytes which are stored only in the cache |
Clean |
Number of bytes which are identical in cache and BFS |
Syncing |
Number of bytes which are being synced |
Data in Slices |
The cache slices which are used for file data blocks |
Get state of a file
$ ls -l $CSCRATCH/example
total 0
-rw-r--r-- 1 user1 chpsadm 8388608000 Feb 4 13:12 input.data
$ ime-ctl --frag-stat $CSCRATCH/example/input.data
File: `/p/cscratch/fs/chpsadm/example/input.data'
Number of bytes:
Dirty: 0
Clean: 0
Syncing: 0
Data on Slices:
In this case the file has no datablocks in the cache. Reading the file will bypass the cache and fetch the data from the underlying $SCRATCH file system piped through the HPST server.
Stage file in the cache (prestage)
$ ime-ctl --prestage $CSCRATCH/example/input.data
$ ime-ctl --frag-stat $CSCRATCH/example/input.data
File: `/p/cscratch/fs/chpsadm/example/input.data'
Number of bytes:
Dirty: 0
Clean: 8388608000
Syncing: 0
Data on Slices: 0 1 2
Here all data blocks are clean, meaning in the cache and in the underlying file system the data blocks are identical.
Warning
Cache Coherence - Changing this file on $SCRATCH will cause data inconsistency.
Write file into the cache
$ cat $CSCRATCH/example/input.data > $CSCRATCH/example/result.data
$ ime-ctl --frag-stat $CSCRATCH/example/result.data
File: `/p/cscratch/fs/chpsadm/example/result.data'
Number of bytes:
Dirty: 8388608000
Clean: 0
Syncing: 0
Data on Slices: 2
The data of this file is stored in the cache only:
$ ls -l $CSCRATCH/example/result.data $SCRATCH/example/result.data
-rw-r--r-- 1 user1 chpsadm 8388608000 Feb 4 14:52 /p/cscratch/fs/chpsadm/example/result.data
-rw-r--r-- 1 user1 chpsadm 0 Feb 4 14:52 /p/scratch/chpsadm/example/result.data
Warning
Cache Coherence - Changing this file on $SCRATCH will cause data inconsistency.
Stage data out (sync)
$ ime-ctl --sync $CSCRATCH/example/result.data
$ ime-ctl --frag-stat $CSCRATCH/example/result.data
File: `/p/cscratch/fs/chpsadm/example/result.data'
Number of bytes:
Dirty: 0
Clean: 8388608000
Syncing: 0
Data on Slices: 2
Now all data blocks are identical in the cache and in the underlying file system.
Warning
Cache Coherence - Changing this file on $SCRATCH will cause data inconsistency.
Delete synced data from the cache (purge)
$ ime-ctl --purge $CSCRATCH/example/result.data
$ ime-ctl --frag-stat $CSCRATCH/example/result.data
File: `/p/cscratch/fs/chpsadm/example/result.data'
Number of bytes:
Dirty: 0
Clean: 0
Syncing: 0
Data on Slices:
No data block of this file is in the cache any more. The file can again be changed on the underlying $SCRATCH file system.
IME native Interface
In the previous section the POSIX interface was described which is realized by a Linux FUSE mount. But to get the best performance out of the CSCRATCH there is a native interface available (C library) which can be used in compute jobs.
Note
The native IME interface can also be used through MPI-IO or libraries that use MPI-IO. To achieve this, the MPI-IO code needs to be compiled using ParaStationMPI, which under the hood will employ the IME native interface.
Warning
IME as a product has been discontinued by DDN. Furthermore, official support for the HPST will end on the 31st of March 2024. We highly recommend avoiding the effort to port any code to the below mentioned IME native examples. POSIX performance should be sufficient, while MPI-IO compiled with ParaStationMPI should reach within a few percent of the performance of IME native access.
The following example demonstrates how to create and sync a file in the CSCRATCH using the native interface.
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <fcntl.h>
#include <ime_native.h>
void my_exit(const char *msg, int ret)
{
if (ret)
fprintf(stderr, "%s : err=%s", msg, strerror(ret));
ime_native_finalize();
exit(ret);
}
#define FILENAME "ime:///p/scratch/chpsadm/example/ime_native-small.dat"
#define NUM_INTEGERS 255
#define IO_LENGTH (NUM_INTEGERS * sizeof(int))
int main(void)
{
int fd;
int buf[NUM_INTEGERS];
ssize_t nbytes = 0, rc;
/* Initialize the IME native client. */
ime_native_init();
/* Open a file via IME. */
fd = ime_native_open(FILENAME, O_RDWR | O_CREAT, 0666);
if (fd < 0)
my_exit("open failed", errno);
/* Write a small amount of data to IME. */
while (nbytes < IO_LENGTH)
{
rc = ime_native_write(fd, (const char *)buf, IO_LENGTH);
if (rc < 0)
my_exit("ime_native_write failed", errno);
nbytes += rc;
}
/* Synchronize data to IME service. */
if (ime_native_fsync(fd))
my_exit("ime_native_fsync failed", errno);
/* Initiate synchronization to the BFS. This operation is non-blocking. */
if (ime_native_bfs_sync(fd, 1))
my_exit("ime_native_sync failed", errno);
if (ime_native_close(fd))
my_exit("ime_native_close failed", errno);
my_exit("done", 0);
}
The only thing that must be adjusted is the target file name: #define FILENAME "ime:///p/scratch/.../ime_native-small.dat" which is the absolute path in the underlying file system $SCRATCH (NOT the CSCRATCH mount point!!!).
Compile the code
#prepare environment
[user1@jsfl01 native]$ ml GCC ParaStationMPI
# compile
[user1@jsfl01 native]$ gcc -I /opt/ddn/ime/include -L /opt/ddn/ime/lib -Wall -O2 -o ime_native_example-small ime_native_example-small.c -lim_client
# Or Using MPI
[user1@jsfl01 native]$ mpicc -I /opt/ddn/ime/include -L /opt/ddn/ime/lib -Wall -O2 -o ime_native_example-small ime_native_example-small.c -lim_client
Execute job
[user1@jsfl01 native]$ salloc --globres=fs:cscratch@just --nodes=1 --account=chpsadm --time=00:20:00
salloc: Pending job allocation 188432
salloc: job 188432 queued and waiting for resources
salloc: job 188432 has been allocated resources
salloc: Granted job allocation 188432
salloc: Waiting for resource configuration
salloc: Nodes jsfc090 are ready for job
# job execution
[user1@jsfl01] srun --nodes 1 --ntasks-per-node=1 $SCRATCH/example/ime_native_example-small
[user1@jsfl01]$ ls -l $CSCRATCH/example/ime_native-small.dat $SCRATCH/example/ime_native-small.dat
-rw-r--r-- 1 user1 chpsadm 1020 Feb 7 16:41 /p/cscratch/fs/chpsadm/example/ime_native-small.dat
-rw-r--r-- 1 user1 chpsadm 1020 Feb 7 16:41 /p/scratch/chpsadm/example/ime_native-small.dat
[user1@jsfl01]$ ime-ctl --frag-stat $CSCRATCH/example/ime_native-small.dat
File: `/p/cscratch/fs/chpsadm/example/ime_native-small.dat'
Number of bytes:
Dirty: 0
Clean: 1020
Syncing: 0
Data on Slices: 2
Job submission when using $CSCRATCH
It is important to add fs:cscratch@just to the globres variable when allocating or submitting a job. When set the variable will prevent Slurm from allocating resources when the HPST system is unavailable.
To check the availability, use the command salloc show-globres.
[user1@jsfl01]$ salloc --show-globres
GLOBAL RESOURCES:
[fs]
fastdata@just
home@just
cscratch@just
project@just
scratch@just
[fs_set:default]
home@just
project@just
scratch@just
[fs_set:all]
fastdata@just
home@just
cscratch@just
project@just
scratch@just
AVAILABLE RESOURCES:
fastdata@just ON
home@just ON
cscratch@just ON
project@just ON
scratch@just ON