Data Storage Linking¶
Research in Jülich is very diverse, as is the data generated from our activities. Ranging from as small as a few kilobyte, it’s easy to reach petabyte for datasets.
Obviously, those big piles of data are likely immutable and unmovable. It makes more sense to link to such data instead of uploading it to a central storage location (unless there is a very good use case).
Datasets in Jülich DATA satisfy the FZJ metadata schema. It contains a field Storage Location URL, enabling linking to individual data files, archives, snapshots, services or inventories.

Contributors Guide to Data URLs¶
When you create or add to a dataset, you are a contributor. Contributors are eligible to edit metadata and can provide the storage links as URLs.
Let’s talk about how URLs work and then how to get them.
What is a URL?¶
“Uniform Resource Locations” (URLs) are a best practice to express where a certain asset resides. A common example is any website address, like an arbitrary example as “http://foo.fz-juelich.de/path/to/bar.html?parameter=hello#shelf-A01”
Creating a URL is fairly easy. Just follow this generator scheme:
![strict digraph {
node [shape=plaintext, fontname="Arial", fontsize=10];
{
node [shape=underline];
rank = same;
scheme [label="protocol\n(scheme):"];
loc [label="network\nlocation:"];
path [label="path:"];
query [label="(opt.)\nquery:"];
anchor [label="(opt.)\nanchor:"]
}
{
rank = same;
protos [shape=box, label="choose one:\nhttp\nhttps\nsmb\nftp\nipfs\n..."];
}
{
rank = same;
prot [shape=plaintext, label="http://"];
host [label="foo.fz-juelich.de"];
barpath [label="/path/to/bar.txt"];
q [label="?parameter=hello"];
a [label="#shelf-A01"];
}
scheme -> protos -> prot
loc -> host;
path -> barpath;
query -> q;
anchor -> a;
}](../_images/graphviz-27e3873d4c1389090f7c0bc25774dec7ac3b2da7.png)
What is a good URL?¶
Imagine you possessed an expensive, yet rarely used tool for a moment. You store it in a shelf in a special tooling cabinet. Each time you use it, you care about putting it back to the very same place. Now your lab assistant uses it without your knowledge and stores it in another cabinet. You swear to god about consequences when you find your tool after searching for hours months later.
This little analogy is the same for data URLs. It’s expensive in terms of time and effort to structure and store your data. Having a link to it is nice, but when it can break easily, you’ll be in trouble next time you want to use them.
The following list defines key aspects to keep an eye on when adding URLs to your dataset. Some common examples how to craft URLs are given below, too.
Warning
You’ll have a hard time starting to think about the structure of your URLs from scratch, with no support from your institute but facing a deadline for a paper. Do this early, write it down. Go create a data management plan now, e. g. using our DMP-Tool.
Good URLs for data storage comprise from:
- Are as specific and atomic as feasible (called “deep”).
- Are as non-breakable as possible. Lack of maintenance is directly proportional to reusability and scientific credit.
- Are providing repeatable and predictable results on access. Data keeps unchanged on reads, no matter when or how often.
- Are never changing any data on access, only enable retrieval of data (free from “side effects”).
- Are presenting a landing page with further documentation only as a last ressort, e. g. when data is by its nature or storage inaccessible over any network.
One consequence from this is, that you should have a 1:1 relation between URLs and files linked to your dataset. That might be tedious and not a good choice for every use case, but you should “know the rules well, so you can break them effectively.” Adding more than a single URL is easy, just press that little “+” button.
Linking to Data Locations¶
The following examples are only a limited description of how to link to existing data in various storage locations. Below examples are completely arbitrary and your mileage may vary, depening on your data, your institute, your intentions and believes.
Feel free to contribute more examples (e. g. using a HTTP query for a data snapshot from a database), by creating an issue in the guides JuGit project first.
Data accessible via Browser (HTTP)¶
Let’s assume you are using some kind of data publishing platfrom (like DataPub run by JSC) and uploaded some data. Now you want to create a dataset, resulting in a citeable data publication for a paper you are about to publish.
Let’s copy the URLs to the data files (one at a time), as our platform is run by professional admins and not subject to change (good URLs, see above):
(The example is made from data accessible here: https://datapub.fz-juelich.de/slts/rollesbroich/data/simulation_results)
When creating the dataset, you may provide a URL (or multiple in our case) by pasting into the metadata field:
After saving your dataset, you may find the URLs in the datasets metadata (as clickable links):

Data accessible via network share (SMB/CIFS)¶
In many institutes, data from experimentation, analysis, simulation and other research activities is made available via network “shares” or “drives”.
Often such shares are mounted under Windows as a drive with some letter, like
X:\. If not mounted, they are commonly accessed with a UNC path like
\\srv.fz-juelich.de\sharename\path\....
Obviously this is not a URL, but it can be transformed into one.
When using a mounted drive, you need to look for the server name, share and path in the details of the mount. Replace the drive letter with the network path and continue.
Example: Replacing
X:\\with\\zb0001.zb.kfa-juelich.de\Freigabe-Diverses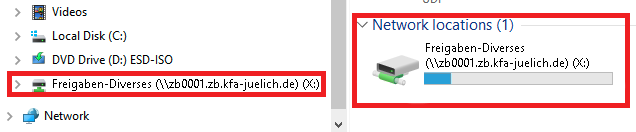
Replace any
\with a/.Replace the leading
//withsmb://Your resulting URL should look like
smb://srv.fz-juelich.de/sharename/path/...
Data accessible on physical media only¶
Some types of data might not be accessible over a network. Think of media like printed images or physical media like compact discs, tapes or drives. Some data storage might contain very sensible data and must not see an ethernet cable.
In these cases it’s impossible to provide a (machine-)accessible URL. Instead, a catalogue or inventory documents data location when seeking access. Plenty of options to build these. You should choose one allowing to create accessible HTTP URLs (applying the above good URL rules).
Lets look at a poor scientist’s solution for this. You can create a page on your institutes website, containing some text enhanced with linkable anchors:
<h3>Storage Room 1</h3>
This room contains all our scientific data, stored on disks, assorted in shelves.
<h4 id="rA">Rack A</h4>
Find this rack to the left when entering the room.
<h5 id="rAs1">Shelf 1</h5>
<h6 id="rAs1d1">Disk 1</h6>
<p>
This disk contains volatile data of hazardous materials.
Please handle with care and keep the disk dustfree.
More details about contained data can be found on Jülich DATA.
Add more metadata or link to the dataset, when you keep
and maintain it in Jülich DATA. Many options.
</p>
<h5 id="rAs2">Shelf 2</h5>
...
<h5 id="rAs3">Shelf 3</h5>
...
<h4 id="rB">Rack B</h4>
...
<h4 id="rC">Rack C></a></h4>
...
After creating this page, you could use https://fz-juelich.de/iek/iek-123/data/our_data.html#rAs1d1 as a storage location URL (see that anchor?). Obviously, this is not a very good URL when compared to the criteria above. You really should think about using asset management systems if you have more than a handful of items.
Curators Guide to Data URLs¶
Decentralized data managers (DDM) of the institutes can configure their dataverses to fullfil the requirements of their contributing researchers. Links to data might not be necessary everywhere.
You can also provide a default value in a template or even move the field to a community specific metadata schema, helping scientists to insert links more easily. Please get in touch in case of questions.
Mandatory Storage URL¶
By default and design, the data storage URL is optional in the core metadata schema of Forschungszentrum Jülich.
If you as a decentralized data manager (DDM) plan on using data linking for datasets in particular dataverses, you may configure the field as mandatory. To make datasets FAIR, we encourage you to have at least some usable references to data in any data publication.
To enable the field as mandatory, edit the dataverses “General Information” and change the metadata configuration.
Hint
Sub-Dataverses may override the setting both ways!
Linking vs Integrating¶
“Uniform Resource Locators” (URLs), more commonly known as “website address” or “link”, are prone to break and rott. Websites are moved, legacy systems tend to silently go away. The links to external storage have to be maintained for continued data quality and reuse.
Instead of using links, a deeper integration between data storages in institutes and Jülich DATA is achievable using multi location storage, enabled per dataverse. It will look like data is local to the repository, while it still resides in an institutional storage system. As of mid 2020, this is possible by using object storage.
Another option for a tighter integration between remote storage and Jülich DATA is by using a Trusted Remote Storage Agent. This is not production ready, but the community would love more use cases. For the recent status of TRSA, in June 2020, see this presentation: https://youtu.be/LHyiA3JeiwE?t=1485
Relaxing Link Practices¶
As outlined above, it will relax a curator’s mind if storage location URLs are as persistent as possible. Storing data in places writeable by anyone at any given time is prone to failure for long term accessibility of data.
Ideally all data from the scientific output should be write-once or at least should be switched into this mode, once it starts “cooling down” (less frequent access, research done, …).
Of course any storage that contains data which is part of a data publication, needs to fullfil the requirements of being kept for 10+ years (good scientific practice).
Depending on usage scenarios, it might be easier to create bundles of data files like using a ZIP/TAR/… archive and link to it. Please keep in mind that you should describe all data in detail, where standards like BagIt, ro-crate (Research Object Crate) are extremly helpful.
ro-crates don’t have to be compressed and may exist as a folder. Pointing the
storage location URL to the ro-crate-metadata.jsonld file is a good idea and
reduce vastly the amount of work to link to the data.
Standards like Oxford Common File Layout even allow the creation of repository-like data infrastructures.
For physical media, you should target building an asset management system and plan ahead with people’s worktime to maintain the vault.