 |
Scalasca
(Scalasca 2.2.2, revision 13327)
Scalable Performance Analysis of Large-Scale Applications
|
|
Scalasca
(Scalasca 2.2.2, revision 13327)
Scalable Performance Analysis of Large-Scale Applications
|
While summary profiles only provide process- or thread-local data aggregated over time, event traces contain detailed time-stamped event data which also allows to reconstruct the dynamic behavior of an application. This enables tools such as the Scalasca trace analyzer to provide even more insights into the performance behavior of an application, for example, whether the time spent in MPI communication is real message processing time or incurs significant wait states (i.e., intervals where a process sits idle without doing useful work waiting for data from other processes to arrive).
Trace collection and subsequent automatic analysis by the Scalasca trace analyzer can be enabled using the -t option of scalasca -analyze. Since this option enables trace collection in addition to collecting a summary measurement, it is often used in conjunction with the -q option which turns off measurement entirely. (Note that the order in which these two options are specified matters.)
SCOREP_TOTAL_MEMORY setting)! Otherwise, you may easily fill up your disks and suffer from uncoordinated intermediate trace buffer flushes, which typically render such traces to be of little (or no) value!For our example measurement, scoring of the initial summary report in Section Optimizing the measurement configuration with the filter applied estimated a total memory requirement of 55 MiB per process (which could be verified by re-scoring the filtered summary measurement). As this exceeds the default SCOREP_TOTAL_MEMORY setting of 16 MiB, use of the prepared filtering file alone is not yet sufficient to avoid intermediate trace buffer flushes. In addition, the SCOREP_TOTAL_MEMORY setting has to be adjusted accordingly before starting the trace collection and analysis. (Alternatively, the filtering file could be extended to also exclude the binvrhs routine from measurement.) Note that renaming or removing the summary experiment directory is not necessary, as trace experiments are created with suffix "trace".
% export SCOREP_TOTAL_MEMORY=55M
% scalasca -analyze -q -t -f npb-bt.filt mpiexec -n 64 ./bt.D.64
S=C=A=N: Scalasca 2.2 trace collection and analysis
S=C=A=N: ./scorep_bt_64_trace experiment archive
S=C=A=N: Thu Jan 29 22:29:02 2015: Collect start
mpiexec -n 64 [...] ./bt.D.64
NAS Parallel Benchmarks 3.3 -- BT Benchmark
No input file inputbt.data. Using compiled defaults
Size: 408x 408x 408
Iterations: 250 dt: 0.0000200
Number of active processes: 64
Time step 1
Time step 20
Time step 40
Time step 60
Time step 80
Time step 100
Time step 120
Time step 140
Time step 160
Time step 180
Time step 200
Time step 220
Time step 240
Time step 250
Verification being performed for class D
accuracy setting for epsilon = 0.1000000000000E-07
Comparison of RMS-norms of residual
1 0.2533188551738E+05 0.2533188551738E+05 0.1479210131727E-12
2 0.2346393716980E+04 0.2346393716980E+04 0.8488743310506E-13
3 0.6294554366904E+04 0.6294554366904E+04 0.3034271788588E-14
4 0.5352565376030E+04 0.5352565376030E+04 0.8597827149538E-13
5 0.3905864038618E+05 0.3905864038618E+05 0.6650300273080E-13
Comparison of RMS-norms of solution error
1 0.3100009377557E+03 0.3100009377557E+03 0.1373406191445E-12
2 0.2424086324913E+02 0.2424086324913E+02 0.1582835864248E-12
3 0.7782212022645E+02 0.7782212022645E+02 0.4053872777553E-13
4 0.6835623860116E+02 0.6835623860116E+02 0.3762882153975E-13
5 0.6065737200368E+03 0.6065737200368E+03 0.2474004739002E-13
Verification Successful
BT Benchmark Completed.
Class = D
Size = 408x 408x 408
Iterations = 250
Time in seconds = 477.71
Total processes = 64
Compiled procs = 64
Mop/s total = 122114.71
Mop/s/process = 1908.04
Operation type = floating point
Verification = SUCCESSFUL
Version = 3.3
Compile date = 29 Jan 2015
Compile options:
MPIF77 = scorep mpif77
FLINK = $(MPIF77)
FMPI_LIB = (none)
FMPI_INC = (none)
FFLAGS = -O2
FLINKFLAGS = -O2
RAND = (none)
Please send the results of this run to:
NPB Development Team
Internet: npb@nas.nasa.gov
If email is not available, send this to:
MS T27A-1
NASA Ames Research Center
Moffett Field, CA 94035-1000
Fax: 650-604-3957
S=C=A=N: Thu Jan 29 22:37:06 2015: Collect done (status=0) 484s
S=C=A=N: Thu Jan 29 22:37:06 2015: Analyze start
mpiexec -n 64 scout.mpi ./scorep_bt_64_trace/traces.otf2
SCOUT Copyright (c) 1998-2015 Forschungszentrum Juelich GmbH
Copyright (c) 2009-2014 German Research School for Simulation
Sciences GmbH
Analyzing experiment archive ./scorep_bt_64_trace/traces.otf2
Opening experiment archive ... done (0.017s).
Reading definition data ... done (0.018s).
Reading event trace data ... done (1.189s).
Preprocessing ... done (2.067s).
Analyzing trace data ...
Wait-state detection (fwd) (1/5) ... done (1.137s).
Wait-state detection (bwd) (2/5) ... done (0.538s).
Synchpoint exchange (3/5) ... done (1.016s).
Critical-path & delay analysis (4/5) ... done (0.888s).
Propagating wait-state exchange (5/5) ... done (0.475s).
done (4.065s).
Writing analysis report ... done (0.137s).
Max. memory usage : 175.965MB
*** WARNING ***
9982 clock condition violations detected:
Point-to-point: 9982
Collective : 0
This usually leads to inconsistent analysis results.
Try running the analyzer using the '--time-correct' command-line
option to apply a correction algorithm.
Total processing time : 7.628s
S=C=A=N: Thu Jan 29 22:37:15 2015: Analyze done (status=0) 9s
Warning: 2.968GB of analyzed trace data retained in ./scorep_bt_64_trace/traces!
S=C=A=N: ./scorep_bt_64_trace complete.
% ls scorep_bt_64_trace
scorep.cfg scorep.log scout.log traces.def trace.stat
scorep.filt scout.cubex traces traces.otf2
After successful trace collection and analysis, the generated experiment directory scorep_bt_64_trace contains the measurement configuration scorep.cfg, the measurement log file scorep.log and a copy of the filtering file scorep.filt. In addition, an OTF2 trace archive is produced, consisting of the anchor file traces.otf2, the global definitions file traces.def and the per-process data in the traces/ directory. Finally, the experiment also includes the trace analysis reports scout.cubex and trace.stat, as well as a log file storing the output of the trace analyzer (scout.log).
The Scalasca trace analyzer also warned about a number of point-to-point clock condition violations it detected. A clock condition violation is a violation of the logical event order that can occur when the local clocks of the individual compute nodes are insufficiently synchronized. For example, a receive operation may appear to have finished before the corresponding send operation started – something that is obviously not possible. The Scalasca trace analyzer includes a correction algorithm [1] that can be applied in such cases to restore the logical event order, while trying to preserve the length of intervals between local events in the vicinity of the violation.
To enable this correction algorithm, the --time-correct command-line option has to be passed to the Scalasca trace analyzer. However, since the analyzer is implicitly started through the scalasca -analyze command, this option has to be set using the SCAN_ANALYZE_OPTS environment variable, which holds command-line options that scalasca -analyze should forward to the trace analyzer. An existing trace measurement can be re-analyzed using the -a option of the scalasca -analyze command, avoiding the need to collect a new experiment:
% export SCAN_ANALYZE_OPTS="--time-correct"
% scalasca -analyze -a mpiexec -n 64 ./bt.D.64
S=C=A=N: Scalasca 2.2 trace analysis
S=C=A=N: ./scorep_bt_64_trace experiment archive
S=C=A=N: Thu Jan 29 22:37:16 2015: Analyze start
mpiexec -n 64 scout.mpi --time-correct ./scorep_bt_64_trace/traces.otf2
SCOUT Copyright (c) 1998-2015 Forschungszentrum Juelich GmbH
Copyright (c) 2009-2014 German Research School for Simulation
Sciences GmbH
Analyzing experiment archive ./scorep_bt_64_trace/traces.otf2
Opening experiment archive ... done (0.005s).
Reading definition data ... done (0.009s).
Reading event trace data ... done (1.349s).
Preprocessing ... done (2.063s).
Timestamp correction ... done (0.683s).
Analyzing trace data ...
Wait-state detection (fwd) (1/5) ... done (1.170s).
Wait-state detection (bwd) (2/5) ... done (0.570s).
Synchpoint exchange (3/5) ... done (1.009s).
Critical-path & delay analysis (4/5) ... done (0.893s).
Propagating wait-state exchange (5/5) ... done (0.502s).
done (4.150s).
Writing analysis report ... done (0.185s).
Max. memory usage : 207.742MB
# passes : 1
# violated : 2679
# corrected : 18791313
# reversed-p2p : 2679
# reversed-coll : 0
# reversed-omp : 0
# events : 263738186
max. error : 0.000072 [s]
error at final. : 0.000000 [%]
Max slope : 0.010000000
Total processing time : 8.580s
S=C=A=N: Thu Jan 29 22:37:25 2015: Analyze done (status=0) 9s
Warning: 2.968GB of analyzed trace data retained in ./scorep_bt_64_trace/traces!
S=C=A=N: ./scorep_bt_64_trace complete.
Similar to the summary report, the trace analysis report can finally be postprocessed and interactively explored using the Cube report browser, again using the scalasca -examine convenience command:
% scalasca -examine scorep_bt_64_trace INFO: Post-processing trace analysis report... INFO: Displaying ./scorep_bt_64_trace/trace.cubex...
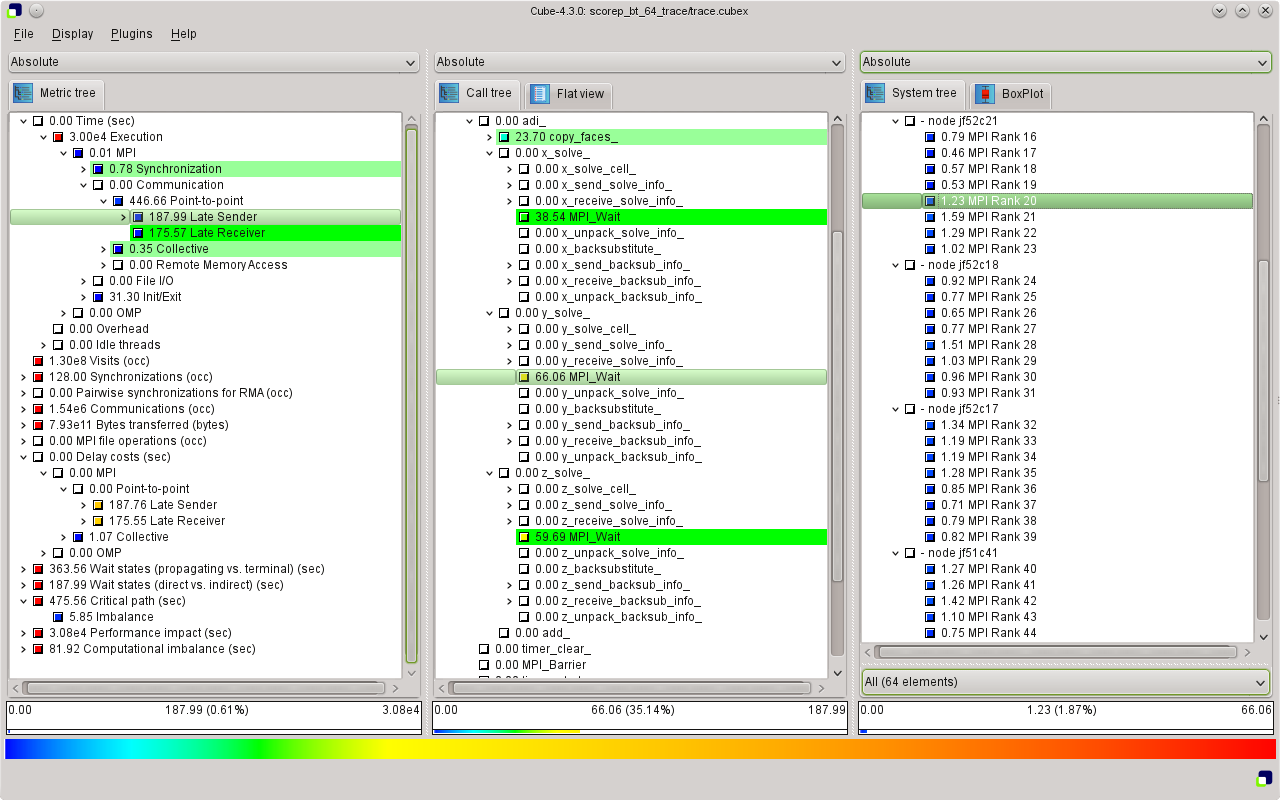
The report generated by the Scalasca trace analyzer is again a profile in CUBE4 format, however, enriched with additional performance properties. Examination shows that roughly half of the time spent in MPI point-to-point communication is waiting time, equally split into Late Sender and Late Receiver wait states (see Figure TraceAnalysis). While the execution time in the solve_cell routines looked relatively balanced in the summary profile, examination of the Critical path imbalance metric shows that these routines in fact exhibit a small amount of imbalance, which is likely to cause the wait states at the next synchronization point. This can be verified using the Late Sender delay costs metric, which confirms that the solve_cells as well as the y_backsubstitute and z_backsubstitute routines are responsible for almost all of the Late Sender wait states. Likewise, the Late Receiver delay costs metric shows that the majority of the Late Receiver wait states are caused by the solve_cells routines as well as the MPI_Wait calls in the solver routines, where the latter indicates a communication imbalance or an inefficient communication pattern.
 |
Copyright © 1998–2015 Forschungszentrum Jülich GmbH,
Jülich Supercomputing Centre
Copyright © 2009–2015 German Research School for Simulation Sciences GmbH, Laboratory for Parallel Programming |