 |
Cube GUI User Guide
(CubeGUI 4.4.4, revision 18494)
Introduction in Cube GUI and its usage
|
|
Cube GUI User Guide
(CubeGUI 4.4.4, revision 18494)
Introduction in Cube GUI and its usage
|
CUBE is a presentation component suitable for displaying performance data for parallel programs including MPI and OpenOpenMP applications. Program performance is represented in a multi-dimensional space including various program and system resources. The tool allows the interactive exploration of this space in a scalable fashion and browsing the different kinds of performance behavior with ease. CUBE also includes a library to read and write performance data as well as operators to compare, integrate, and summarize data from different experiments. This user manual provides instructions of how to use the CUBE display, how to use the operators, and how to write CUBE files.
The version 4 of CUBE implementation has an incompatible API and file format to preceding versions.
CUBE (CUBE Uniform Behavioral Encoding) is a presentation component suitable for displaying a wide variety of performance data for parallel programs including MPI and OpenOpenMP applications. CUBE allows interactive exploration of the performance data in a scalable fashion.cube_ Scalability is achieved in two ways: hierarchical decomposition of individual dimensions and aggregation across different dimensions. All metrics are uniformly accommodated in the same display and thus provide the ability to easily compare the effects of different kinds of program behavior.
CUBE has been designed around a high-level data model of program behavior called the cube performance space. The CUBE performance space consists of three dimensions: a metric dimension, a program dimension, and a system dimension. The metric dimension contains a set of metrics, such as communication time or cache misses. The program dimension contains the program's call tree, which includes all the call paths onto which metric values can be mapped. The system dimension contains the items executing in parallel, which can be processes or threads depending on the parallel programming model. Each point 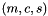 of the space can be mapped onto a number representing the actual measurement for metric
of the space can be mapped onto a number representing the actual measurement for metric 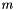 while the control flow of process/thread
while the control flow of process/thread 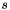 was executing call path
was executing call path 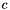 . This mapping is called the severity of the performance space.
. This mapping is called the severity of the performance space.
Each dimension of the performance space is organized in a hierarchy. First, the metric dimension is organized in an inclusion hierarchy where a metric at a lower level is a subset of its parent. For example, communication time is a subset of execution time. Second, the program dimension is organized in a call-tree hierarchy. However, sometimes it can be advantageous to abstract away from the hierarchy of the call tree, for example if one is interested in the severities of certain methods, independently of the position of their invocations. For this purpose CUBE supports also flat call profiles, that are represented as a flat sequence of all methods. Finally, the system dimension is organized in a multi-level hierarchy consisting of the levels: machine, smp node, process, and thread.
CUBE also provides a library to read and write instances of the previously described data model in the form of a cubex file (which is a tar ed directory). The file representation is divided into a metadata part and a data part. The metadata part describes the structure of the three dimensions plus the definitions of various program and system resources and stored in a form of an tar file anchor.xml inside of the cubex envelope. The data part contains the actual severity numbers to be mapped onto the different elements of the performance space and stored in binary format in various files inside of the cubex envelope.
The display component can load such a file and display the different dimensions of the performance space using three coupled tree browsers (figure gui). The browsers are connected in such a way that you can view one dimension with respect to another dimension. The connection is based on selections: in each tree you can select one or more nodes. For example, in Figuregui the Execution metric, the adi call path node, and Process 0 are selected. For each tree, the selections in the trees on its left-hand-side (if any) restrict the considered data: The metric nodes aggregate data over all call path nodes and all system items, the call tree aggregates data for the Execution metric over all system nodes, and each node of the system tree shows the severity for the Execution metric of the adi call path node for this system node.
If the CUBE file contains topological information, the distribution of the performance metric across the topology can be examined using the topology view. Furthermore, the display is augmented with a source-code display that shows the position of a call site in the source code.
As performance tuning of parallel applications usually involves multiple experiments to compare the effects of certain optimization strategies, CUBE includes a feature designed to simplify cross-experiment analysis. The CUBE algebra is an extension of the framework for multi-execution performance tuning by Karavanic and Miller and offers a set of operators that can be used to compare, integrate, and summarize multiple CUBE data sets. The algebra allows the combination of multiple CUBE data sets into a single one that can be displayed and examined like the original ones.
In addition to the information provided by plain CUBE files a statistics file can be provided, enabling the display of additional statistical information of severity values. Furthermore, a statistics file can also contain information about the most severe instances of certain performance patterns – globally as well as with respect to specific call paths. If a trace file of the program being analyzed is available, the user can connect to a trace browser (i.e. Vampir) and then use CUBE to zoom their timelines to the most severe instances of the performance patterns for a more detailed examination of the cause of these performance patterns.
The following sections explain how to use the CUBE display, how to create CUBE files, and how to use the algebra and other tools.
To invoke GUI for CUBE profile exploration one uses command:
cube [-disable-plugins] [-preload] [-lastN] [-help] filename.cubex
A list of main options:
-preload -help %todo
CUBE provides the option of displaying an online description for entries in the metric tree via a context menu. By default, it will search for the given HTML description file on all the mirror URLs specified in the CUBE file. In case there is no Internet connection, the Qt-based CUBE GUI can be configured to also search in a list of local directories for documentation files. These additional search paths can be specified via the environment variable CUBE_DOCPATH as a colon-separated list of local directories, e.g.,
CUBE_DOCPATH=/opt/software/doc:/usr/local/share/doc
Note that this feature is only available in the Qt-based GUI and not in the older wxWidgets-based one.
To prevent CUBE from trying to load the HTML documentation via HTTP or HTTPS mirror URLs (e.g., in restricted environments were outbound connections are blocked by a firewall and the timeout is taking very long), the environment variable CUBE_DISABLE_HTTP_DOCS can be set to either 1, yes or true.
Cube searches for plugins in the directory "cube-plugins/" below the installation directory. This is the place where the predefined plugins are installed. With the environment variable CUBE_PLUGIN_DIR one can specify a user defined place where third-party plugins are installed. If CUBE_PLUGIN_DIR contains a colon or semicolon separated list of paths, these paths are prepended to the default search path.
CUBE C++ library allows to control the way it loads the data using the environment variable CUBE_DATA_LOADING. Following values are possible:
N last used data rows are kept in memory. N is specified via environment variable CUBE_NUMBER_ROWS Subsections:
 |
Copyright © 1998–2017 Forschungszentrum Jülich GmbH,
Jülich Supercomputing Centre
Copyright © 2009–2015 German Research School for Simulation Sciences GmbH, Laboratory for Parallel Programming |